We are putting the finishing touches on a substantial battery upgrade at The Vale at the moment. The old Redflow based 280kWh battery array has been removed, and replaced with almost 400kWh (80 modules) of Pylontech US5000 units.
This is because of the demise of Redflow, a company I put a great deal of time, effort and money in to, over a very long period.
The 28 x ZBM2 array at The Vale did alright for some years, but the time has come to swap in something that I can obtain ongoing support for.
Hence the deployment of 80 x Pylontech US5000 modules – which are now up and running.
The Redflow array was inside our main farm building, inside a wooden room… because Redflow ZBM’s are super-resistant to fire (to creating it, or to amplifying a fire around them).
Because the worst case with Lithium batteries is an ugly exothermic chemical fire, these new modules have been built in to custom-wired, insulated, shipping container (to create a physically separate ‘module’ beside our main farm shed building). The container is cabled back in to the very same Victron Energy system that was built around the previous Redflow batteries.
I’ll write more about this updated system later, and provide some more photos of it… but it felt like the right time to briefly note that things have changed in this regard at The Vale.
This is an epilogue, to document the outcome, in fairness to Qantas.
All of the issues noted below in this blog post, with the exception of the electronic case management IT tool at Qantas being pretty sucky, are now resolved.
I spent an hour or so being called a number of times by Qantas escalations staff (their escalations team title seems to be ‘Executive Relations’), and we worked through and satisfactorily resolved every open issue that I had. The refunds I asked for have been initiated. My online access works again.
There are a few object lessons for Qantas in this, in my view, that I’ll just take note of, here, in the hope that Qantas Executive Relations is able to take steps to improve these aspects of the customer experience in the future.
#1: The customer-facing aspect of the case handling (i.e. support ticket) handling system used by Qantas is really pretty bad:
Email sent in does not get an initial automatic response with the case number in it, so a followup to a submission that hasn’t got yet got a reply is… impossible.
When a case *is* followed up, the case number does not appear to be automatically added, but rather it looks to have to be manually added by a human. I suggest this because of my ongoing issues with receiving case responses with an invalid case number (discovered when my response in turn is rejected and discarded as described in the post below). Huge frustration results.
The support ticketing system appears to be ‘home brew’ and pretty rubbish, from a customer standpoint. Qantas would do well to invest the trivial sum involved (for their size) in switching to a professional cloud-based case management tool like Zendesk. This would be easy to do, rapid to do, and would radically improve the quality of their online customer support overnight.
#2: Qantas need a customer-accessible escalation mechanism that is not twitter
Writing this post and then tweeting it actually worked as a customer escalation mechanism.
In the absence of a proper, directly accessible escalation mechanism (with a professional online case number/ticket handling system attached, as a pre-requisite), customers will keep using twitter and public embarrassment to get the attention of a high level ‘Executive Relations’ person.
This is inefficient for all concerned and reputationally damaging for Qantas.
Instead, Qantas should have a very clear online path to raise an *escalation* ticket (or to flag, for escalation, any existing open case), with that path linked into a ticketing system that workswell… and then have appropriate (senior, empowered, on-shore) staff work that ticket queue.
The resulting improvement in both customer satisfaction and overall customer service (if systemic issues are then fixed) at Qantas would be both rapid and profound.
I am not guessing or speculating here. This is what I did at Internode when that company was ‘my life’…and it really worked.
And now, on to the original blog post…
Complaints handling can be hard when IT systems get in the way
Yes, this is one of those complaint posts about customer service. I’ve written it because this won’t fit in a tweet, but once I’ve written it down here, I can tweet this blog to Qantas instead…this form of escalation is something I’m driven to because of a lack of apparent escalation paths on the Qantas site itself.
For a couple of decades, I ran, and cared for, for a large customer-focussed company – an Internet Services Provider company called Internode. This has, I contend, given me a better than average appreciation of the merits and frustrations inherent in getting customer support ‘right’.
Major world airlines like Qantas have to have pretty good IT systems to survive in the modern world, but – it is still the case that when it comes to customer facing interactions, their IT systems have the sort of problematic faults that are just so very silly (and in most cases, relatively simple to improve).
Sometimes broken IT customer-facing systems can feel, to customers, as if they are actively (and successfully) defending the company from hearing the attempts of customers to get help.
One thing that Qantas could really use (for those who aren’t members of the Chairmans Lounge) is an escalation path for times when attempts to get their customer-facing systems to help you just… don’t help you, and for when you feel like you’re whacking your head against a brick wall.
…And yes, I was in the ‘Chairmans Lounge’ for some years – and that was wonderful in terms of escalation … they have a dedicated escalations team (and a magic email and magic phone number) for when stuff goes awry. I think I miss that escalation path more than the physical Chairmans Lounges…
The story so far
We recently returned from short overseas holiday – a luxury that we hadn’t properly enjoyed since, well, ‘COVID’. Because I have the good fortune of having done pretty well in business, I buy ‘non economy’ seats on airlines when I’m flying with airlines.
There were three of us who poured ourselves off of QF2, an A380, in from London via Singapore, into Sydney, on (cough) ‘very expensive tickets’.
Our connection from Sydney back home to Adelaide (in business class seats) was scheduled (by Qantas) for 1h40m after our landing time into Sydney. Our A380 into Sydney landed slightly ahead of time (tailwinds) and we breezed through customs almost instantly (first aircraft to land into Sydney after curfew). Easily in time to make our connection.
Alas, we then spent most of the next hour standing at the baggage carousel watching other bags come off, before ours finally appeared. We arrived at the domestic bag drop counter just as our domestic flight (on the other side of the airport) was boarding. No chance to get that plane.
(This is despite our bags being tagged with ‘First Class / Priority’ tags, and our bags had been on the same plane all the way from London. It is unclear what the purpose of those tags is, because it didn’t deliver us any… priority…)
The next business class seats to Adelaide were in 8 hours time, so Qantas downgraded us and shoe-horned us into 3 separate rows at the back of the next plane instead.
After we got home, it occurred to me that a downgrade not of our making should really result in Qantas refunding us the ticket price difference for the lost business class seats that their baggage handling had made it impossible for us to use. So I filed a form on the Qantas web site requesting that this be done.
Some days later, I got a response that asked for photos of our boarding passes.
Our boarding passes.
Pieces of cardboard.
In 2023.
Pieces of cardboard that I may or may not still have (genuinely not sure), but that are definitely not in the same state as I am this week (people who buy tickets on airlines… travel to places far away… who knew?)
I wrote back to say (in summary): “Hey, really? Cardboard? Here’s the PDF copy of my original entire itinerary, and your own systems will record exactly which aircraft you moved us to, and will all note exactly which 3 seats, distributed around the very back of the aircraft, we sat in…surely that’s enough data for you to process the refund?”
Now, this is where the fun really starts. In response to that reply, I got a generic error message email – as below:
Now, this email is remarkable to me (with my customer service history) in many ways, including:
All I did was hit ‘reply’ to an email I got from a Qantas staff member. That reply had a ticket number in both the subject line and the message body. Clearly that number was wrong.
How the hell is the wrong number in an email back from Qantas? Are the replies hand written or cut/paste driven rather than coming out of their actual support system? How much effort does it take to break your own internal ticketing system like that?
The email (above) says that my reply to an active case has been thrown in the bin. That hardly increases my love of Qantas customer service. How about turning my email into a new ticket so that a human at Qantas bloody reads it and finds the original support ticket and link them? It’s not that hard, you have my email address!
I tried replying again – and (of course) I got the very same ‘Your email is so important to us that we just threw it away, screw you’ response that I got the first time (as above).
So… I’ve been successfully locked out of my original support ticket because I don’t know what the ticket number is, and Qantas botched communicating that one specific item of information back to me.
I’m sure that someone inside Qantas will mark the original support ticket down, one day, as ‘customer never bothered to reply, they must not care’. Argh!!
And (you guessed it) – it gets worse!
All I could really do is to create a new support ticket via their web form, and to use that to explain the silliness noted above and ask them to help me with that refund request (again).
When I tried to fill in my Qantas Frequent Flyer information on their complaints web form, this happened:
Yes, that’s right. Sometime in the last few days, something in the Qantas IT system now broke my ability to log in online at all.
Argh. I really can’t log in any more:
To be very clear, this is not an authentication error, it is a ‘something is broken, no soup for you!’ message coming from deep inside the Qantas IT world.
I had no choice but to call the Frequent Flyer Centre.
So I did.
After the mandatory 20 minutes of listening to why my call is important to Qantas, I spoke to a helpdesk person who was… totally unable to assist.
She walked me through the usual checks to see if I was a just being silly, then tried to look at the account herself. At this point she started to make confused noises about whatever she was seeing on her screen. She put me on hold. She came back.
And… (deep breath)… all she could do to ‘help’ was to say she would log a support ticket about the issue and have someone in IT take a look at it.
She warned me that the usual ticket turnaround time is… 3-5 days.
So … that’s 3-5 days when I can’t check or change my bookings online and can’t book new flights – when Qantas’ systems are successfully defending me from any further use of my credit card to pay them more money.
I booked half a dozen flights a few days ago… pity me if I needed to do that today, I’d be doing it on the phone (and being charged a ‘service fee’ penalty for annoying their phone team instead of… doing it myself online… argh!)
Deeper, in 3-5 days time, there’s no guarantee they’ll actually fix the problem.
For all I know, I might get another email back with another invalid support ticket number in it, asking me for some critical item of data in order for them to fix their problem with their IT system.
And now, this…
I have a feeling that the ‘login prohibited’ issue might be related to a weird message I’ve had on my screen whenveer I log in, for a few months now.
It tells me there’s something (unspecified) wrong with my profile, and includes a link to my personal profile, so I can fix the (unspecified) problem.
I filed a support ticket about that, ages back, and got an email reply offering to call me about it if I would tell them when was a good time to call.
I did that and they did not call me.
They sent me another email claiming I didn’t answer their call (hint: not true, no missed calls, nothing) and asking me to call them instead, and to quote my support ticket number over the phone.
I did that.
After half an hour of being painfully guided through every single aspect of my profile, the support staff member could only agree with me that nothing was wrong with it, and all she could offer me was (and I am really not kidding) …
… instructions for how to lodge a new support ticket about my problem.
Argh!
That issue remains to this day. Unresolved, and apparently unresolvable.
Let’s not even start to talk about the other support ticket I filed (a few weeks ago) with no reply received at all. That is the one where I asked Qantas to convert a flight credit into a refund because I hit ‘credit’ by mistake when I was canceling a (fully refundable) fare I no longer needed. Apparently that support ticket is off in some other pocket of purgatory, waiting for a change in the weather.
Meantime, for the lack of an escalation path, I am here on the Internets whacking keys in frustration, in the hope of some catharsis, while my curry cooks in the Thermomix.
On 25 Jan 2023 I held a tour of The Vale’s energy system ( https://aeva.asn.au/events/450/) for members of AEVA in Tasmania. We had a lot of people (and a lot of EV’s) turn up 🙂
There was a slide show the same evening in Devonport where I found myself telling the story of my personal journey with EVs over the years, alongside the story of building the Vale’s Renewable Energy System (and mentioning a few aircraft here and there too).
Chances are that you have been suffering the same issue that i have, for more than a year now… and that has been driving me a bit mad!
I have had an issue for more than a year, that’s been driving me a bit mad…
This issue is that current versions of the AXIS WebOS user interface interact badly with Safari, such that Safari keeps popping up a login window over and over (and over and over). You can hit ‘cancel’ to dismiss the login box, but it keeps on coming back, and back and back. Its infuriating.
When I asked AXIS support for help, they didn’t (help) me at all. They just told me to use another browser (which works, but I don’t want to use another browser).
I have finally found the fix, and I wanted to write it down in case it helps others. I found the fix today on an AXIS web page, in reference to a specific camera and IOS, but it turns out that the fix works in general with all AXIS cameras and with Safari on MacOS X as well as on IOS. Yay!
To fix this issue on IOS:
To use AXIS OS web interface with iOS 15 or iPadOS 15, go to Settings > Safari > Advanced > Experimental Features and disable NSURLSession Websocket.
To fix this issue on MacOS X:
If the ‘Develop’ menu is not visible in Safari on the Mac, first make it appear by doing this:
Go to Safari > Preferences, click Advanced, then select “Show Develop menu in menu bar”
Now, turn off the same ‘Experimental Feature’ (NSURLSession Websocket) by finding it and un-checking it under the Develop > Experimental Features menu.
Subtitle: “Ubiquiti Auto-Optimise Breaks stuff again” (it is also responsible for this).
The Scenario
I have been having persistent, annoying and sustained issues with older Sonos devices dropping off of my WiFi network after a while. This is on a network driven entirely with Ubiquiti UniFI products (switches and access points connected to a UDM-Pro).
The older Sonos products would disappear regularly from view from the Sonos Apps.
Power cycle them and they return, but then any time from a few minutes to a few hours later… they’re gone again. Power cycle yet again. Rinse and Repeat. Grrr.
The Problem
The Ubiquiti ‘auto-optimize’ function strikes again – and breaks stuff. Hmmm.
The ‘optimize’ fuction modifies the minimum data rate for 2.4Ghz ‘beacon’ frames to a rate above the 802.11b default. Doing this breaks WiFi connectivity for devices that can only use 802.11b. The older Sonos models use 802.11b. So … this breaks them.
The Fix
(1) Turn off ‘auto-optimize’ (under Advanced settings in the Network settings page).
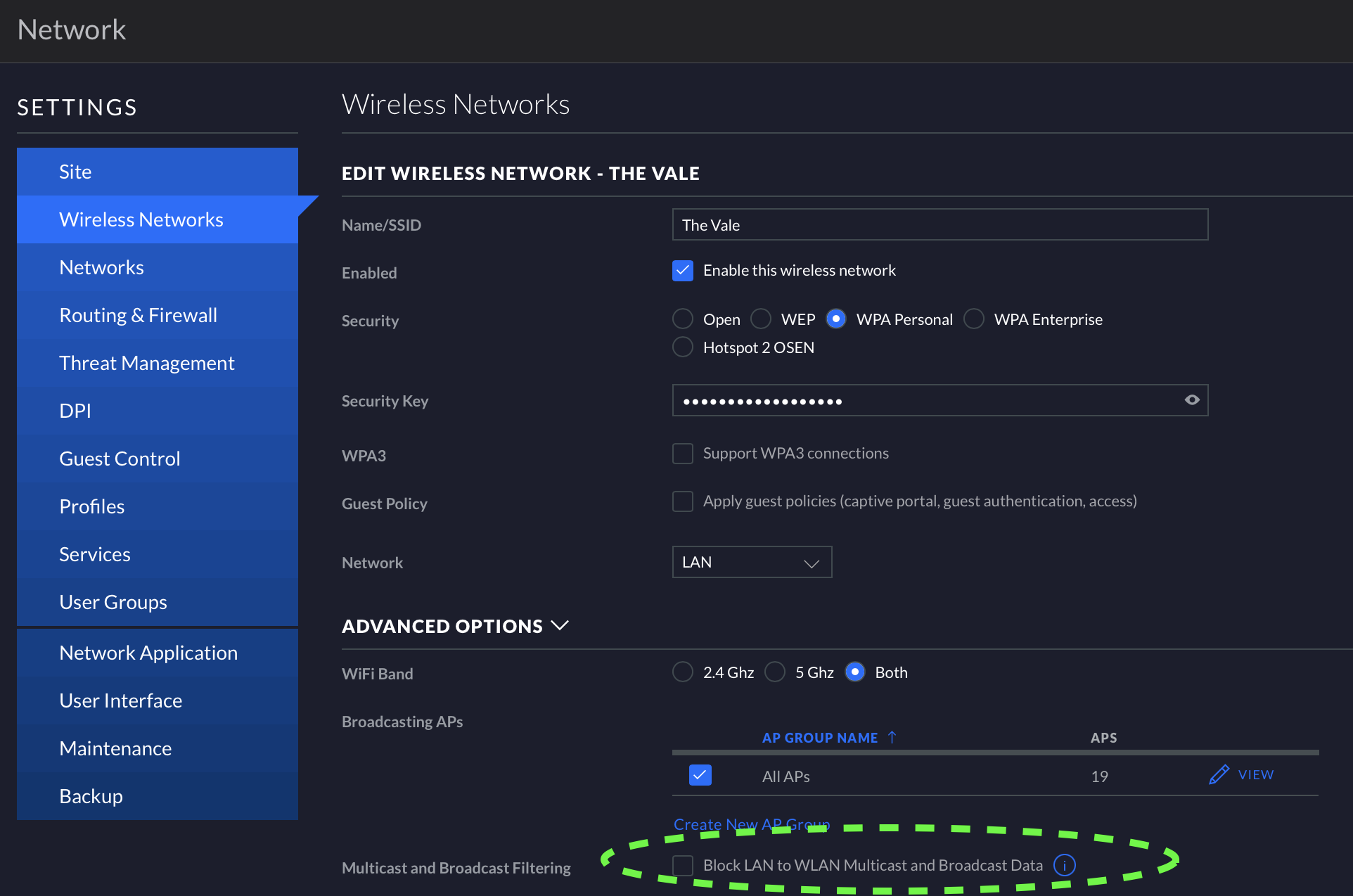
(2) Turn off the checkbox “2G Data Rate Control” on the Wireless Network page for your WiFi SSID concerned (see images below) to restore working 802.11b WiFi connectivity
The Details (if you need or want them)
I have Sonos One devices and (older) Sonos Play:5 devices. Its the Play:5’s that kept going away.
Importantly the older Sonos units are 2.4Ghz 802.11b only units devices… they can’t talk on 5Ghz (but the UniFi AP’s can bridge them to control devices running on newer devices and newer bands).
After a lot of head scratching, I realised that ‘something’ had changed a critical setting on my UDM-Pro.
The setting that was changed was the one (in the Wireless Network page) called “2G data rate control”.
This had been turned on (by the ‘auto optimizer’) and set to 5.5Mb/s minimum:
This is a minimum beacon rate that (as it says on the page) causes “Limited range and limited connectivity for 802.11b devices”
The older Sonos devices are 802.11b 2.4Ghz only devices! Hence this setting is guaranteed to break Sonos Network access – and to keep breaking it. Argh.
So: The fix is to set that minimum data rate back down to 1Mb/s, at which point the on-screen text changes to “Full Device Compatibility and Range”:
Fixed! Yay!
It is simpler (and more direct) to just disable the rate changing function entirely (by un-checking the box ‘Enable Minimum data rate control’.
However, I wanted to point out the changes in that explanatory text with the screen images above. These underscore that the optimiser (which is on by default) really does make changes that break older WiFi device access (and without warning the user that this is what will happen).
Note that on the UDM (vs the UDM-Pro), there are different checkboxes to restore 802.11b connectivity. On that platform, you (again) turn off the optimiser and then under your WiFi network configuration page you’ll find a switch hiding in the “Advanced” section “Enable Legacy Support”. This switch is explained with the text ‘Enable legacy device support (i.e. 11b)’. Duh. So turn that on (i.e. do enable the legacy device support).
I’m sure this is breaking connectivity for other devices too – there are going to be lots of little gadgets in people’s networks that are older or simpler and that only support 802.11b. If you want those to work… you’ll want to enable that legacy support.
Update: We have some wall mounted underfloor heating controllers (with WiFi) in the house… that were unreliable and just couldn’t hold a WiFi connection. You know where this is going … now they work just fine.
I’m writing this down in the hope that someone else trying to solve this issue via some random ‘Googling’ may find this article and that it may save them some time… compared to how long it took me to solve this!
I run a moderately sized UniFi based network consisting of a UDM-Pro, 10 UniFi switches on a fibre ring, and 19 UniFI Wireless LAN access points.
I turned on automatic software updates on the UDM-Pro a while ago, and I am presuming that the issue that has occurred here is as a result of the latest software that got auto-installed (UniFi UDM Pro Version 1.10.4 and ‘Network’ version 6.5.53).
It took me a few days to figure out that the UniFi network was the cause of broken printer operation and also the cause of our on-site Sonos audio devices all ceasing to work.
The way the ‘breakage’ occurs is subtle – some, but not all, peer to peer IP traffic over the wireless LAN was being silently dropped. Broken things included Multicast based protocols (such as AirPrint) and also initial connection establishment (with the ARP protocol’s broadcast frames apparently being filtered as well)
This impacted some network nodes but not to all of them.
The way this first manifested was that our printer stopped working. It didn’t work wireless-to-wireless, and it didn’t work when I tried cabling it into a switch and accessing it via wireless on my laptop.
The failure to work even on a wired connection convinced me the printer was just… b0rked, and that it was time to replace it.
In a similar timeframe, the Sonos audio devices in our house also stopped working. I didn’t initially register the timing coincidence with the printer fault because, frankly, Sonos network communication sometimes get flakey ‘all by itself’…and I had shelved that issue to figure out ‘later’.
In the meantime, we actually went and bought a new printer! When I fired that up, it failed to work as well (!). Ah hah… ‘lightbulb moment’. It wasn’t the printer. It was something far more fundamental about the network. It had to be.
I started digging deeper, with that new data point (that it wasn’t actually the printer at fault). Eventually, via various network diagnostic steps, I figured out that a strange network failure mode was the real issue.
Since it seemed to be impacting broadcast and multicast frames, I started looking for, and adjusting settings related to that functionality in the UDM-Pro.
Eventually I landed on the fix:
Turn OFF the ‘AUTO OPTIMIZE NETWORK’ setting under the Settings->Site menu. This is necessary in order to unlock the ability to change the next setting
Turn OFF the checkbox called “Block LAN to WLAN Multicast and Broadcast Traffic” on the Settings->Wireless Networks-> [ Your network name here ] -> EDIT WIRELESS NETWORK page
Turn this off to fix the fault
Ii is that latter setting that is doing the damage. When on, it is literally blocking things as fundamental as ARP broadcast packets so that IP connections can’t even be established reliably between hosts on the local network. Hosts can all talk to ‘the wider Internet’ just fine, but they can’t talk to each other.
I didn’t take any manual action to break the network – all I did was leave automatic OS updates turned on and a few days ago – these mysterious faults appeared.
See the screen shots below to help you find where those settings located on the UniFi Web console interface.
As soon as I took the steps above, the UDP-Pro re-provisioned all my UniFI WiFi access points and everything started working again – printer started working perfectly, Sonos started working fine. I proved this is the issue by turning the setting back on and – bingo – instant network faults. Off again…and it all works again.
I hope this helps someone else!
I’ve reported it to Ubiquiti because I think they need to urgently make a further update to fix this pretty fundamental bug, and hopefully they’ll indeed fix it.
In the meantime, I hope this post helps someone else avoid the head scratching (and/or throwing out perfectly good printers and/or Sonos units!).
This is where the ‘AUTO-OPTIMISE’ switch is (turn off to unlock the following setting change)Turn off the checkbox at the bottom of this screen to fix the WLAN network fault
Update-1:
12 Dec 2021: The ‘Network’ version has been incremented to 6.5.54 as at 12 December 2021.
Some good has been done in this incremental release: It has been kindly pointed out to me that a workaround is in there now for small sites, so at least small sites (less than 10 APs) won’t suffer this issue any longer.
The following comment has been added to the release notes for 6.5.54 (from here):
Enable multicast block if Auto-optimize is enabled, and there are more than 10 APs assigned to SSID.
My site does have more than 10 APs assigned to the SSID concerned. So, for me, 6.5.54 still shows the issue (which explains why, in my testing, the fault wasn’t fixed in 6.5.54).
This is a good thing – sites with less than 10 APs will now no longer see this bug.
However: The bug still exists and this workaround is just hiding it until it leaps out and bites sites in the tail when they expand to 10 or more APs (on the same SSID). Argh.
This feature (when enabled) is breaking fundamental aspects of TCP/IP network operation on a routine basis.
There are two issues here.
The first is that it is quite possible for two hosts to be associated to two different APs while being in the same physical location. Picture a printer on a desk and a user of that printer who has walked in from the AP next door (and is still associated with the AP next door).
Or picture a location that happens to just be at the intersection of two roughly equidistant APs (which is going to happen all the time on a network with more than 10 APs)
When this happens, the outcome for users in terms of Multicast/Broadcast activity is going to become intermittent – sometimes it’ll block packets, and sometimes (if host hosts do happen to both be on the same AP) it might work…for a while. And then stop again mysteriously later.
This intermittency was evident in my initial testing (and now I appreciate why).
As people make their networks larger (and of course for anyone who already was running a large network and who has auto-updated), they will see this mysterious problem happen both without warning and without explanation.
I actually think that’s worse… because now its a fault that unexpectedly occurs when the network expands beyond a certain point. Pity the IT guy who has to figure that one out, with the sole clue being that one line in the Network 6.5.54 release notes.
The signature example of the seriousness of this problem is something completely fundamental to working TCP/IP networks:
This feature blocks ARP packets
As a result, the establishment of working unicast connections between hosts in the local network (e.g. as fundamental as connecting to a printer and using it) will not work reliably (or in many cases, will not work at all)… which is where we came in.
It also means, for instance, that if you try to ‘ping’ another host on your local IP range, that ping might work, or it might not, depending on where the other host is, across your network (or on whether it has roamed to another AP that is reachable in the same physical location).
Debugging that sort of thing could drive people a bit crazy.
Without consideration of this, the functionality of the feature in general is pretty broken.
I get the point, and in implementing this, Ubiquiti means well, but it has not been fully thought out and it is going to be the cause of nasty (and worse, subtle) network faults on a continuing basis until more effort is put in to how this feature works (and to allowing the operator to select Broadcast and MultiCast packet types to continue to forward!).
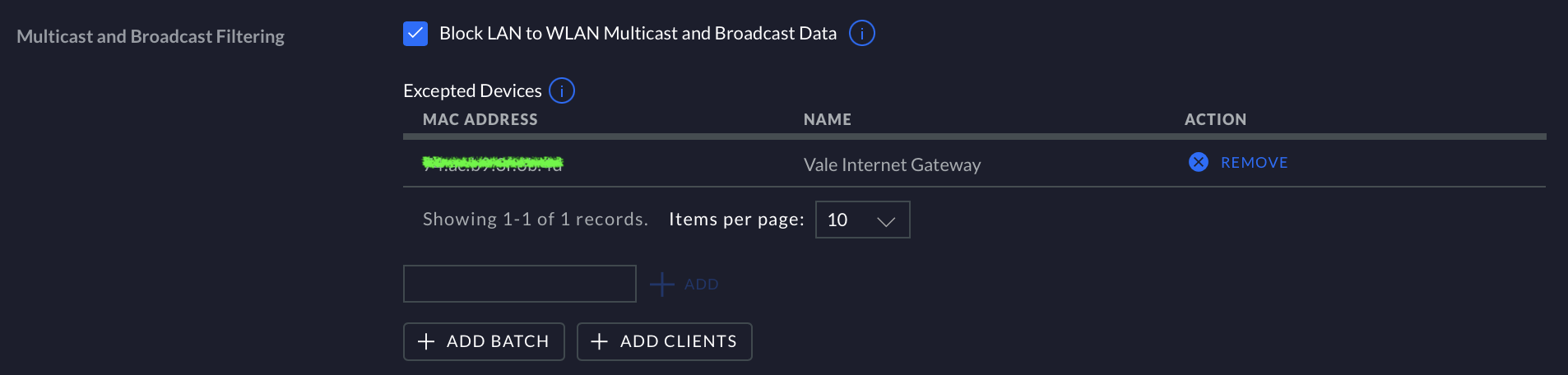
I’ve noticed that when turned on, this feature allows for the addition of hosts by MAC address that are still able to be visible network wide:
You can add HOSTS to exclude from blocking but you can’t add PROTOCOLS (such as ARP) to exclude!
That is a tacit admission of how this feature breaks stuff.
Adding hosts to the exclude-from-blocking list by MAC address is well meaning, but network operators will be perpetually chasing their own tails as people add printers or audio devices (or replace busted ones). Maintaining a MAC address block list is just a ‘make work’ activity that no network administrator (or their users) needs. Not ever.
Ubiquiti has implemented extensive device ‘fingerprinting’ of devices over time. This meansthey can figure out what things are. If this feature is going to exist (and be silently turned on without warning!!) at all, then it has to be configurable in terms of device types and/or broadcast/multicast protocols that can be whitelisted, not hosts.
Again the issue here is that there are protocols (like ARP – argh) that you just can’t block between APs at all, without breaking fundamental aspects of how TCP/IP networks work.
This isn’t good, and until it is further improved, the underlying problem remains. The change in .54 does help a bit, for most people… but for the people it doesn’t help, it has made the real problem (that the feature itself is un-tenable as it stands) both harder to find (and hence harder to fix).
The other day, I was talking with someone about the wonders (and the satisfaction) of operating a large renewable energy system at our Tasmanian farm, and how I get to charge up my electric motor glider and go flying on sunshine, and how we’ll replace all the farm machinery that burns diesel with electric vehicles as soon as someone will sell that electric farm machinery to me (all of which is true).
One of our children kindly (and accurately) popped that balloon for me with a single sentence, by saying: ‘Yeah, but you also fly a turbojet aircraft’.
The plane we fly is a most wonderful beast called a Pilatus PC12 NGX. The convenience, speed, capability and sheer reach is just fantastic. I also get huge personal satisfaction from flying it. However, ‘satisfaction’ is not a Carbon offset.
This conversation lead me to pose a question to myself:
Can our solar array create enough renewable electrical energy to completely offset the carbon dioxide emissions involved in flying our aircraft?
I decided to work it out.
I don’t claim to be any sort of saint – the idea is just to see if it is possible to achieve something like ‘Carbon Neutrality’ by offsetting the aircraft Carbon emissions with solar array Carbon savings.
I’ve tried to get the numbers right here (and they make sense to me)… but if I’m getting the sums wrong somehow (or misunderstanding the source data), I’d be very keen to find that out. That’s one of the reasons why I’ve posted it all here… to subject these calculations to the light of day.
Source Data
My annual flying hours in the PC12: 200 (average over the last 3 years)
Average hourly fuel burn for my mission profile: around 250 litres per hour
Average energy generated per annum per 1 kW of array size at The Vale: 1340kWh
Thus for a 200kW array we will make about 200 x 1340 = 268,000 kWh annually (Source: LG Solar Output Calculator ; My ‘actuals’ to date are highly consistent with that calculator).
Whether we use it on site for buildings or for electric tractors, or whether we export it, this is all energy that isn’t being generated somewhere else, hence it is net electrical energy we are adding to the total renewable electrical generation of the world.
Our actual export figure right now is above 90%, though that will reduce as we add more electric farm machinery over the coming years – in the process of progressively reducing our diesel burn figure to zero.
Our farm is in Tasmania. This complicates things because the Tasmanian energy grid is already incredibly ‘green’ – see below:
However: Tasmania has one substantial inter-connector to Victoria (Basslink) and there is another big one, MariusLink, on the way. Those interconnections allow Tasmania to sell electricity into the Victorian grid. So we’ll use the Victorian grid as our imputed destination.
The current official figure for Carbon Dioxide emission per kWh generated in Victoria is 1.13Kg per kWh (Source: The Victorian Essential Services Commission).
Now we have all the numbers we need. It is time to start doing some maths.
Annual PC12 Aircraft Carbon Dioxide Emission Created
200 hours x 250 litres per hour x 2.52 Kg per litre = 126,000 Kg
Annual 200kW Solar Array Carbon Dioxide Emission Avoided
268,000 kWh x 1.13 Kg = 302,840 Kg (or 2.4 times the PC12 emissions)
Outcome
Assuming the energy destination is the Victorian energy grid, we are offsetting the aircraft Carbon footprint more than twice over! This was a (good) surprise to me.
That said, Victoria has a particularly ‘dirty’ grid. Sigh…coal…sigh.
What happens if we make this harder, by using the global average Carbon intensity value for energy grids instead of the value for Victoria?
Taking 126,000Kg and dividing it by 0.5Kg per kWh, we get a clean energy generation target of 252,000kWh.
This is still substantially below the 302,840Kg annualised energy production from the solar array at The Vale. Even on this ‘global average’ Carbon intensity basis, we are (more than) completely offsetting the Carbon footprint of my annual PC12 flying time.
One other thing we can derive from all of this is the ratio between flying-hours-per-year and the needed solar array size (for a solar array in Tasmania, and using the higher bar of 0.5Kg offset per kWh generated):
Dividing 252,000 kWh by 200 hours means 1260 kWh of annual energy production is needed per annual-flying-hour. Given that each kW of array size generates 1340kWh per year (in Tasmania), we need 1260/1340=0.94 kW of solar array size per annual-flying-hour in the aircraft to achieve a full offset of the annual flying time concerned.
To put it another way, we need 94kW of solar array size to offset (on a continuing basis) each 100-hours-per-year of flying time in the aircraft.
Time for a bigger calculation.
How much solar would it take to offset the entire global aviation industry?
According to this source, around 900 million tons of carbon dioxide were emitted annually due to global aviation immediately pre-COVID (assume we wind up ‘back up there’ post COVID… eventually).
So that is 900,000,000t x 1000Kg = 900,000,000,000 Kg of CO2. Yikes.
Dividing by 0.5 means we would need to generate 1,800,000,000,000 kWh of electricity from (new) renewable sources to offset the entire global aviation industry.
We are a small investor in a big project: “Sun Cable” . The first major project for Sun Cable will build around 20 Gigawatts (!) of solar arrays in the wilds of the Northern Territory, and export most of it to Singapore.
Yes, really. If you don’t think big, you don’t get big.
The LG Solar Calculator says one could expect 1940kWh of electricity per kW of solar array in Alice Springs. Multiplying 1940kWh by 20,000,000kW gets us 38,800,000,000 kWh (38,800m kWh) per year.
This is just my back of the envelope approximation, and the real outcome in terms of output energy from Sun Cable could well differ somewhat from that estimation for a whole host of rational technical reasons, including things as obvious as energy loss over long transmission paths, that the project isn’t actually in Alice Springs, etc etc.
So: We’ll de-rate that annual production estimate by an arbitrary 25% to fold in some pessimism and call it a ‘mere’ 29,100,000,000 kWh per annum.
Time for the punchline:
1,800,000,000,000 / 29,100,000,000 = around 60 (these are all huge approximations – so – measure with a micrometer, mark with chalk, cut with an axe)
The punchline (and this was also a surprise to me) is this:
It could take just 60 Sun Cable-sized projects to offset the Carbon emissions of the entire global aviation industry
The world could actually do that. If we can make one, we can make sixty.
The Sun Cable web site says that the initial project for the company is an AUD$30+ billion project (US$21bn at the time of writing).
Sixty of those would be a mere US$1260 billion (US$1.3tn). An impossibly large number to consider? Well, the four largest American companies each have a market cap well above this level.
Apple has enough cash on hand (at the time of writing) to build the first 9 of these mega-projects without even taking out a loan. Remember, too, that these will be highly profitable projects, not donations. They won’t merely mitigate carbon – they’ll (literally) power the world.
We have enough sunlight. We have enough land. What we need is enough ambition.
I delivered a (virtual) talk at a recent (August 2021) battery technology conference in South Africa.
Having taken a look at the recording, I think it has come out as a reasonably clear and cogent summary of the current state of play in terms of the deployment of, and the scaling of, Redflow ZBM2 based energy storage systems.
The talk runs for about half an hour, and you can find it here:
Deploying the worlds smallest flow battery at grid scale
I’ve recently received my first SpaceX Starlink connection kit and fired it up in the wilds of Adelaide, South Australia. I’ve been figuring out how it all works and commencing some efforts toward a mid term project of deploying another Starlink service in a remote wilderness site in the future.
When I fired up my service, I had an initial issue wth it that really had me scratching my head, so I felt there was merit in documenting what happened and how to fix it.
Despite the warnings in the user documentation about potential issues if the cable length is extended, I had initially tested the service by sitting Dishy on the back lawn and plugging the (long!) ethernet/data cable into an RJ45 socket that I already had on the outside of my house (intended for an outdoor PoE WiFI access point). The other end of that RJ45 socket emerges on a patch panel in my study, where I plugged in the Starlink power brick and WiFi adaptor.
Dishy in the backyard on the lawn for initial testing
I tried that, and it worked really nicely. Immediate acquisition of signal and 300M/35M average speeds (!), with short term peak speeds above 400/40 (!!)… wow. I mean seriously… wow.
Having done that test, I got my friendly local sparky to install Dishy on the roof in a suitable location, and to run my ethernet cable into the roof space, and out into the study directly, as the permanent installation. I tried really hard to ‘do it right’, following the instructions about not cutting or extending the ethernet cable.
Dishy on the roof
When I plugged it all back together (no cable connections, using only the original cable run back into the power brick), the service didn’t work.
What I saw on the Starlink app was a fault indication… ‘Poor Ethernet Connection’
Starlink: Poor Ethernet Connection fault report
This fault showed up despite the connection being directly into the power brick, in accordance wth the instructions…
The Poor Ethernet Fault appeared despite no intermediate patching
Worse, the word ‘poor’ was an understatement.
Despite the Starlink App being able to see and control the dish, with Dishy visible in statistical terms on the app, there was in fact zero data flow.
No Internets For Me.
The physical connection from the RJ45 cable into the power brick was not 100% tight, but it didn’t seem terrible, and no amount of jiggling it made any difference to the total lack of service.
A visit from my sparky to re-check for the absence of any cable damage in the installation (and there was none) left us both scratching our heads, until I had one of those counter-intuitive ideas:
The service worked when I had an intermediate set of cable paths and patch points in the data path (and quite long ones). What if I put those back in?
Well, I did that – and – it worked perfectly again(!).
Ah hah.
So that very slightly loose RJ45 connection might just be the issue. Dishy (according to things I’d read online) uses PoE but needs a lot of power (90+ watts), and hence it would need a pretty much perfect RJ45 connection to make this work.
Next, i tried the smallest possible workaround to that slightly loose RJ45 connection on the original equipment…a very short patch lead and an RJ45 joiner:
How to fix a Starlink “Poor Ethernet Connection” – by adding an additional ethernet connection (!)
Bingo – perfect working connection, and it has kept working brilliantly ever since.
If I remove that little patch segment, it fails again. Oh well, it can stay there.
I hope this helps someone else with similar issues…!
This is a really easy fix, and hardly worth getting the hardware replaced by SpaceX when the self-service resolution is so simple, but it is somewhat counter-intuitive (given all the admonishment in the documentation against adding extra ethernet segments).
Update: I reported the issue to Starlink via the support path in the app. I got sent an example photo of what looks like a ‘known’ issue and got asked to check and photograph my own RJ45 plug and socket on the system.
This is what I found on my Dishy plug end when I looked hard at it (and took a careful photo):
Bent pin guide on Dishy’s RJ45 plug end
Well, that’s obviously ‘it’. That’s all it takes.
In response to my photo of that bent RJ45 connector pin, SpaceX are immediately forward-shipping me me an entire new Starlink kit and they have sent return instructions / vouchers for the existing kit.
Not withstanding that I could, in practice, just re-terminate the cable with a new plug, that’d likely void the warranty, so I am happy enough to swap the whole thing out for that reason (to keep the setup entirely ‘supported’).
I’ll have to get my sparky to pull the existing Dishy+cable and install the new one, when that new kit turns up, but – well – I can’t fault the customer service in this case. No arguments, just ‘have a new one’.
Interesting process, and interesting resolution. I wonder if they’ll send me a shiny new square dish this time?
If something is worth doing … it is worth overdoing 🙂
Last night I noticed that my suburb had been upgraded by NBNCo and that Aussie Broadband could now offer me a 1000 megabit per second Internet via NBN HFC at home (The previous NBNCo HFC ‘limit’ at my house was 250 Megabits per second).
Deeper, I was delighted to discover that the Aussie Broadband app allows you to implement a plan/speed change ‘in app’ and has the option to do it ‘right now’.
So I did it ‘right now’ – and – a minute or two later – this:
Wow. Thanks Very Much
Well strap my face to a pig and roll me in the mud…
…that is a really, really pleasant Internet speed to have at home 🙂
I’ve had gigabit fibre Internet at the office for years, but having it right in your house is pretty darn cool. Finally feel like we’re starting to catch up with some other countries.
I don’t think I expected it to take quite that long to get to my house, frankly – but – its here now.
That SpeedTest result is on a wired network port… on an 802.11ac wireless connection to an iMac in another room, I’m maxing out at a lazy 300 megabits or so right now. Finally my WiFi is the speed constraint, and nothing else is getting in the way. WiFi speeds fall off very sharply with distance, which is why I tend to put ethernet ports into any buildings I’m doing any sort of work on. You just can’t beat the speed of a wired connection.
The outcome (even via WiFi) is materially snappier compared to even the 250 Megabit per second service. Its like my office has been for years – click on something and (if it is well connected), then ‘blink’ and it has updated the page completely an instant.
The one bummer is that ‘mere’ 50 megabit per second upload speed – for which I still can’t quite countenance why NBNCo insist on that level of artificial throttling. Speed limiting just to make your ‘business’ products more valuable is the sort of evil tactic we used to complain about Telstra engaging in.
That said, 50 megabits per second upload is still ‘substantial’ and it is the increased upload seed that is actually the major factor in the above-mentioned improved ‘snappiness’ of updates. The extent to which upload speed is a real-world constraint to download performance is still a widely un-appreciated thing.
If this inspires you to move to Aussie Broadband as well, just remember you can type in the magic referral code 4549606 when you sign up, to save yourself (and me!) $50 in the process 🙂


















You must be logged in to post a comment.